
- The Fenced Forest -
← Back to home


What It Takes to Trust a Probabilistic AI in Deep Enterprise
10 mins read


Getting the AI blimp off the ground in deep enterprise
When the business units arrived with a wishlist of AI features, we brought the conversation back upstream to understand what they actually needed. We then drafted a framework to de-risk the inevitable throwaway costs and balance user needs against the hype. Basically helping the team to be prudent.
We then interviewed employees across different functions to see where GenAI was already showing up in their daily work. Those conversations shaped two beta use cases directly:
- Image and text recognition for document digitisation and auto-filling structured data (ironic, considering we’ve had tried-and-true OCR tech for decades but the team was keen measuring its performance).
- Enterprise information analysis and summarisation for several internal knowledge workflows.
Both use cases went through several rounds of co-creation and paper testing before we proceeded with build and rollout. In the months that followed, we monitored feedback closely.
As it rolled in, one of the consistent patterns I captured pointed to accountability fear. If an AI-assisted decision is later questioned, who answers for it? The model can't. And in a bank, that question is never hypothetical.

Accountability fear wasn't a single concern. It sat across multiple layers at once. Compliance exposure, regulatory scrutiny, customer data sensitivity. Each one serious on its own. Together, they made the question of ownership feel genuinely untenable.
Even if users were hypothetically required to use it, every output still needed to be thoroughly checked. So why not just do it themselves?
That pattern surfaced across multiple function and teams. Training gaps, data constraints, tooling limitations, all of it was real and all of it mattered. But underneath those layers was something harder to resolve through infrastructure alone.
What fuelled this lack of trust?
Two fears, not one
The markers of discomfort could be grouped into two broad camps, and they point in different directions:
- The first is the fear of the unknown. GenAI is still, for many, a genuinely novel phenomenon. In a McKinsey survey from 2024, 40% of respondents identified explainability as a key risk in adopting GenAI, yet only 17% said they were actively working to mitigate it ↗. For non-technical users especially, the opaqueness alone was enough to stall adoption. They can't see what’s happening. This doesn't hold up in high-trust environments like healthcare, banking or legal spaces. Every 'why' must be auditable.
- The second is the fear of the known. This group of users aren’t technophobes or ignorant to GenAI. It's that they understand it well enough to be worried of its hallucinations which continues to range from 3–15% depending on domain ↗. In a bank, this error rate isn't a quirk, it's a liability. (Update: Amazon learned this directly. After AI-assisted code contributed to outages causing millions of lost orders ↗, the company introduced a 90-day safety reset with mandatory two-person sign-off on code changes. )The regulated environment just makes the consequences more visible sooner.
Both fears point to the same problem. The model's probabilistic nature is misaligned with the deterministic expectations is a must in enterprise use cases.

Basically, GenAI is built to guess well. Enteprise is built to be right. Those 2 things are in direct conflict.
Telling users to trust the output more isn't an answer. Neither is better onboarding. What if the problem actually demands a way to make the model's behaviour legible? Surfacing its uncertainty, stress-testing its outputs, and putting a human with the right context at the point where the decision gets made. The question isn't whether to use GenAI. It's whether we can design the conditions under which its outputs are genuinely defensible, and I believe that’s where early-stage ‘trust’ are planted.
The Shadow AI contradiction
Worth addressing that Microsoft and LinkedIn's 2024 Work Trend Index ↗ found that 78% of AI users at work bring their own tools through personal accounts. To that, we were deliberate about the mix when recruiting. Some participants had little to no familiarity with GenAI. Others had it quietly folded into their personal routines already.
What both groups shared was the same hesitation once the context shifted. GenAI sits comfortably in casual use, but the moment real consequences attach to the output, trust contracts. That shift in tolerance is probably where the real design problem lives.
The hesitation I observed probably had less to do with not understanding the technology, more with what using it officially actually meant. In a regulated environment, a sanctioned tool means owning what comes out of it. That's a different ask than reaching for a personal tool, and I suspect that gap is what drove the hesitation we kept seeing.
So how do we design for it?
The black box problem
GenAI doesn't reason, it generates the most statistically probable continuation of a prompt. It can be simultaneously fluent and fabricating, which is a liability for anyone producing a defensible recommendation or trying to guarantee outputs are free of bias.
The challenge isn't to hide this ‘black box’ nature, but what if we scaffold it with predictive controls to make outputs low-entropy, explainable, and auditable?
To answer those, I broke the issue down into two parts to be solved.
- Firstly, the GenAI output’s accuracy needs to be measurable. Casual users typically ‘vibe-check’ GenAI output and will take any response that is reasonably sound. To that I moved to find a formal yardstick to measure confidence, one that could be easily used and understood by everyday users. For that I looked to Shannon Entropy↗. It posits that the less predictable a message, the more uncertainty it carries. In a bank, high entropy means unmitigated risk.
- Secondly, the scores needs to derive from an observable structured process. I landed on a 3-stage scaffolding to help manage this entropy shift:
- Stage 1 (Internal Loop Verification): Reduces ‘noise’ (false entropy) by verifying facts. It cleans the data so that the ‘uncertainty’ in the draft isn't just caused by hallucinations.
- Stage 2 (Adversarial Red-Hat Testing): Increases ‘useful entropy.’ By forcing a different perspective, you are introducing new, unpredictable data points (critiques) that your original ‘helpful’ AI might have suppressed.
- Stage 3 (Last Mile Gate/Grounding): This is where you, the human, resolve the remaining entropy. You take the high-entropy (unpredictable) options provided by the AI and use your contextual knowledge to collapse those options into a single, ordered decision.
Making it work: Human as sovereign, AI as the engine
For this I looked to the Cybernetic Control Model ↗ and reimagined it to fit the 3 staged scaffolding.
The idea is to reframe the AI is the processing Engine, fast, generative, pattern-matching at scale. The human is the sovereign Governor with final decision-making authority, responsible for grounding, validating, and contextualising the engine's outputs. The relationship is hierarchical by design, not because AI can't be capable, but because accountability in enterprise contexts has to sit somewhere legible.
This isn't a new insight dressed up in new language. I modelled it around established ML concepts, with direct reference to Constitutional AI ↗, Self-Refine ↗, and LLM-as-a-Judge ↗. and turns them into a portable, parameterised, context-agnostic prompt wrapped in scaffold with human-in-the-loop governance.
What's different now is the urgency, and the specificity of what ‘oversight’ control needs to look like when the engine is a probabilistic, emergent surprise generator rather than a deterministic software tool. (Update: As of 2026, the EU is already phasing in requirements for human-in-loop interactions under the EU Artificial Intelligence Act ↗.)
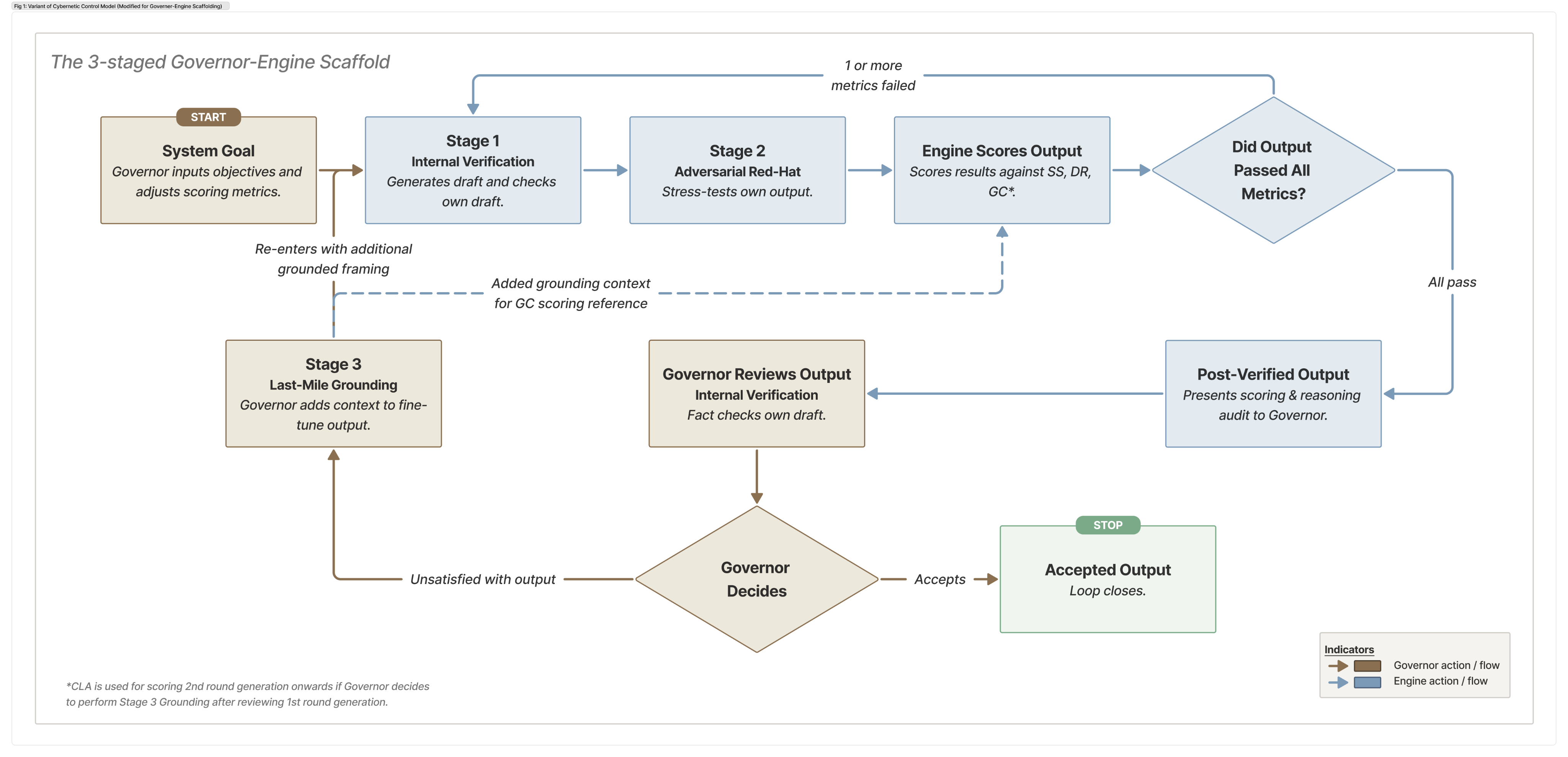
If you want to see how this runs in practice, I made a companion tool that walks through both modes. There's a manual version that takes you through each stage individually, so you can see what the Engine is doing at each step. There's also a master prompt that automates Stages 1 and 2 entirely. The loop runs until parameters are passed. Stage 3 stays manual by design.
A companion tool to test the scaffolding in your own context.
governor-engine-scaffold.netlify.app/
How do we determine whether an output is sufficiently ‘ready’?
After Stage 2, the Engine scores its own output against three checks. If any fail, it loops back. All three must pass before the output reaches the Governor.
- Stress Score (SS): Did it hold up under pressure? Measures how many of the adversarial critiques raised in Stage 2 were actually addressed. The bar is set at 90% by user, 9 out of 10 Red-Hat challenges need a credible response before the output is considered stable.
- Drift Rate (DR): Is it still improving? Tracks how much the output changes between loops. If the change drops below 10%, further looping won't help. The output has plateaued. This does take effect in a clean post-Stage 2 draft generation, and would only start on any recursive loops since it needs a prior version to perform drift checks.
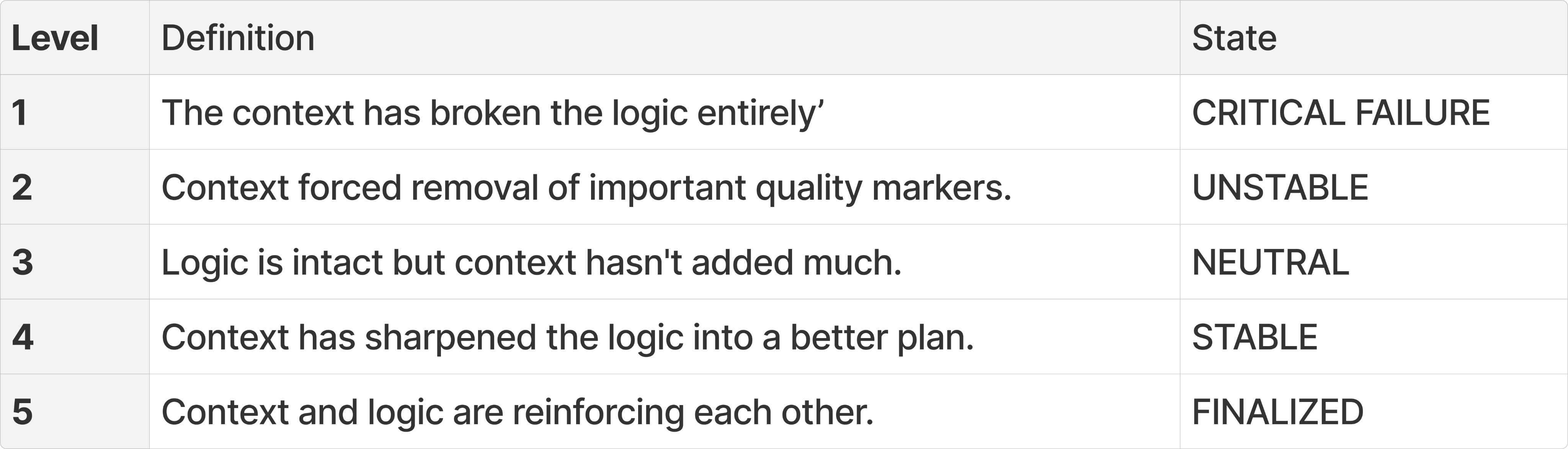
- Grounding Check (GC): Does it hold up in your added context? This only kicks in from the second loop onwards, once the Governor has added grounding context in Stage 3. It measures whether the Engine has taken that context on board and applied it. It ensures that the output logic is sound not just in isolation, but it needs to survive contact with the real constraints you've introduced.Below is a scale I developed for Grounding Check, not an established standard.
3 questions had to be asked after every stage. Did it survive a stress test? Has it stopped changing meaningfully? Does it actually make sense based on added context? If all 3 answers were yes, we moved forward.
In the companion tool, I also repackaged these instructions into a single, LLM-agnostic master prompt with instructions to loop and test recursively until the passing criteria are met.
Below are several competing frameworks and how they measured against the 3-Stage Process. Note that these aren’t rigorous measurements by any means.

A Note on Weaknesses of This Scaffold
In attempt to add rigour, the Governor-Engine Scaffold consumes token heavily (tested on Alphabet’s Gemini and Anthropic’s Claude). However, users are able to adjust passing parameters to fit whatever level of rigour the use case demands. This in theory allows control on token use. In fact, an earlier draft of the diagram required Stage 1 and Stage 2 to run their own recursive checks and loop within each stage. Testing and retesting variants of these master prompts caused me to almost hit the 5-hour limit on Claude Pro.
The obvious next problem to solve is efficiency, which I suspect data scientists and LLM engineers are already working on it.
So what does enterprise trust actually mean?
As I worked through the fears, scaffolding, and metrics, a clearer picture of what trust actually requires started to form. I believe there’s 4 aspects will make it a more palatable for adoption:
- Verification and hallucination control matters most upstream. The ability to detect, measure, and flag inconsistencies before outputs are acted on, not after.
- Closely linked is auditable transparency, not a full explainability layer, which tends to be technically complex and often misleading, but enough of a reasoning trail that a human governor can interrogate the output meaningfully.
- Beyond that, reproducible frameworks. Prompting structures that behave consistently across similar inputs are where prompt engineering disciplines matter most, not for performance, but for predictability.
- And finally, standardised governance artefacts. Design of trust artefacts should be portable, reusable controls that can be adopted across teams rather than reinvented each time a new pilot launches.
None of these are purely technical problems. All of them are, a combination of process, people, and design problems.
The deeper question
I feel organisations getting the most from GenAI aren't the ones who've found a way to trust the model unconditionally. They're the ones who've designed systems where outputs are always accountable to a human with the context, the authority, and the scaffolding to interrogate them. (Update: There’s a growing industry termed Observability).
The irony wasn't lost on us. GenAI was being sold everywhere as the great productivity unlock, and there we were, watching employees hesitate at the threshold. The hype had arrived. The trust hadn't.
This pattern isn't new. The Gartner Hype Cycle↗ has a name for it, every transformative technology ‘crests’ on inflated expectations before the inevitable slide into disillusionment. What follows, for the technologies that survive, is a slower climb built on realistic, hard-won understanding. Just like the Dot-com Bubble, GenAI is no different.
When the ‘crest’ breaks, the loudest voices quiet down and the more useful ones, the practitioners, the level-headed adopters, the people who've actually tried to get the blimp off the ground, start to be heard. Leadership will finally get their GenAI tool for deep enterprise use cases, but probably only after enough pilots stall.
To me, the probabilistic engine is powerful. Taming it isn't about constraining it. It's about knowing exactly who's holding the reins.

I'll also be the first to admit this is one slice of a much larger problem. Properly solving for trust in enterprise GenAI requires a multi-specialist efforts from ML engineers, compliance leads, legal, change management, and many more. This piece approaches it from a design and governance angle, which is a limited one by definition. Take it as solutioning from that vantage point, not a complete answer.
That said, this piece is my attempt at exploring whether that answer can be made portable. It draws on established ML concepts and cognitive science, but the intent was never purely theoretical. I wanted to see if the conditions for trust, verification, auditability, human oversight, could be packaged into something any non-technical staff could pick up, regardless of their technical setup. The companion tool is the practical test of that. Whether it holds in your context is the real question.
A small footnote: after publishing this, Anthropic released /Skills and .md, and I see it as scaffolding that operate on similar principles. Seems that 2026 is shaping up to be the year the industry stops treating human oversight as a philosophical position and starts treating it as an engineering requirement.
Additional reading
- Jerry, B., Moreno, L., and Martínez, P. (2025). Human Oversight-by-Design for Accessible Generative IUIs. Universidad Carlos III de Madrid.
- Codreanu, T. (2025). Cooperation After the Algorithm: Designing Human-AI Coexistence Beyond the Illusion of Collaboration. Imperial College London.


© 2025–2026 Kevyn Leong

- The Fenced Forest -
← Back to home

What It Takes to Trust a Probabilistic AI in Deep Enterprise
10 mins read

In 2024–2025, I worked with business units in a bank to roll-out beta GenAI features into live, high-trust workflows. I saw adoption hesitance. It wasn't just the technology. It was a quieter human problem that showed up consistently across every function that needed deeper unpacking. Project timelines moved, so I never had that luxury.
At my own time, I explored behavioural and theoretical aspects of the outcome. What trust actually requires when the technology is probabilistic but the environment isn't? How can we design systems to earn trust?
The practical account of how we shipped into that environment is covered separately in Shipping to Learn, Not to Impress.
--
Warning: This piece gets into the weeds quickly. I spent too much time and went off the deep end.
Getting the AI blimp off the ground in deep enterprise
When the business units arrived with a wishlist of AI features, we brought the conversation back upstream to understand what they actually needed. We then drafted a framework to de-risk the inevitable throwaway costs and balance user needs against the hype. Basically helping the team to be prudent.
We then interviewed employees across different functions to see where GenAI was already showing up in their daily work. Those conversations shaped two beta use cases directly:
- Image and text recognition for document digitisation and auto-filling structured data (ironic, considering we’ve had tried-and-true OCR tech for decades but the team was keen measuring its performance).
- Enterprise information analysis and summarisation for several internal knowledge workflows.
Both use cases went through several rounds of co-creation and paper testing before we proceeded with build and rollout. In the months that followed, we monitored feedback closely.
As it rolled in, one of the consistent patterns I captured pointed to accountability fear. If an AI-assisted decision is later questioned, who answers for it? The model can't. And in a bank, that question is never hypothetical.

Accountability fear wasn't a single concern. It sat across multiple layers at once. Compliance exposure, regulatory scrutiny, customer data sensitivity. Each one serious on its own. Together, they made the question of ownership feel untenable.
Even if users were hypothetically required to use it, every output still needed to be thoroughly checked. So why not just do it themselves?
That pattern surfaced across multiple function and teams. Training gaps, data constraints, tooling limitations, all of it was real and all of it mattered. But underneath those layers was something harder to resolve through infrastructure alone.
What fuelled this lack of trust?
Two fears, not one
The markers of discomfort could be grouped into two broad camps, and they point in different directions:
- The first is the fear of the unknown. GenAI is still, for many, a genuinely novel phenomenon. In a McKinsey survey from 2024, 40% of respondents identified explainability as a key risk in adopting GenAI, yet only 17% said they were actively working to mitigate it ↗. For non-technical users especially, the opaqueness alone was enough to stall adoption. They can't see what’s happening. This doesn't hold up in high-trust environments like healthcare, banking or legal spaces. Every 'why' must be auditable.
- The second is the fear of the known. This group of users aren’t technophobes or ignorant to GenAI. It's that they understand it well enough to be worried of its hallucinations which continues to range from 3–15% depending on domain ↗. In a bank, this error rate isn't a quirk, it's a liability. (Update: Amazon learned this directly. After AI-assisted code contributed to outages causing millions of lost orders ↗, the company introduced a 90-day safety reset with mandatory two-person sign-off on code changes. )The regulated environment just makes the consequences more visible sooner.
Both fears point to the same problem. The model's probabilistic nature is misaligned with the deterministic expectations is a must in enterprise use cases.

Basically, GenAI is built to guess well. Enteprise is built to be right. Those 2 things are in direct conflict.
Telling users to trust the output more isn't an answer. Neither is better onboarding. What if the problem actually demands a way to make the model's behaviour legible? Surfacing its uncertainty, stress-testing its outputs, and putting a human with the right context at the point where the decision gets made. The question isn't whether to use GenAI. It's whether we can design the conditions under which its outputs are genuinely defensible, and I believe that’s where early-stage ‘trust’ are planted.
The Shadow AI contradiction
Worth addressing that Microsoft and LinkedIn's 2024 Work Trend Index ↗ found that 78% of AI users at work bring their own tools through personal accounts. To that, we were deliberate about the mix when recruiting. Some participants had little to no familiarity with GenAI. Others had it quietly folded into their personal routines already.
What both groups shared was the same hesitation once the context shifted. GenAI sits comfortably in casual use, but the moment real consequences attach to the output, trust contracts. That shift in tolerance is probably where the real design problem lives.
The hesitation I observed probably had less to do with not understanding the technology, more with what using it officially actually meant. In a regulated environment, a sanctioned tool means owning what comes out of it. That's a different ask than reaching for a personal tool, and I suspect that gap is what drove the hesitation we kept seeing.
So how do we design for it?
The black box problem
GenAI doesn't reason, it generates the most statistically probable continuation of a prompt. It can be simultaneously fluent and fabricating, which is a liability for anyone producing a defensible recommendation or trying to guarantee outputs are free of bias.
The challenge isn't to hide this ‘black box’ nature, but what if we scaffold it with predictive controls to make outputs low-entropy, explainable, and auditable?
To answer those, I broke the issue down into two parts to be solved.
- Firstly, the GenAI output’s accuracy needs to be measurable. Casual users typically ‘vibe-check’ GenAI output and will take any response that is reasonably sound. To that I moved to find a formal yardstick to measure confidence, one that could be easily used and understood by everyday users. For that I looked to Shannon Entropy↗. It posits that the less predictable a message, the more uncertainty it carries. In a bank, high entropy means unmitigated risk.
- Secondly, the scores needs to derive from an observable structured process. I landed on a 3-stage scaffolding to help manage this entropy shift:
- Stage 1 (Internal Loop Verification): Reduces ‘noise’ (false entropy) by verifying facts. It cleans the data so that the ‘uncertainty’ in the draft isn't just caused by hallucinations.
- Stage 2 (Adversarial Red-Hat Testing): Increases ‘useful entropy.’ By forcing a different perspective, you are introducing new, unpredictable data points (critiques) that your original ‘helpful’ AI might have suppressed.
- Stage 3 (Last Mile Gate/Grounding): This is where you, the human, resolve the remaining entropy. You take the high-entropy (unpredictable) options provided by the AI and use your contextual knowledge to collapse those options into a single, ordered decision.
Making it work: Human as sovereign, AI as the engine
For this I looked to the Cybernetic Control Model ↗ and reimagined it to fit the 3 staged scaffolding.
The idea is to reframe the AI is the processing Engine, fast, generative, pattern-matching at scale. The human is the sovereign Governor with final decision-making authority, responsible for grounding, validating, and contextualising the engine's outputs. The relationship is hierarchical by design, not because AI can't be capable, but because accountability in enterprise contexts has to sit somewhere legible.
This isn't a new insight dressed up in new language. I modelled it around established ML concepts, with direct reference to Constitutional AI ↗, Self-Refine ↗, and LLM-as-a-Judge ↗. and turns them into a portable, parameterised, context-agnostic prompt wrapped in scaffold with human-in-the-loop governance.
What's different now is the urgency, and the specificity of what ‘oversight’ control needs to look like when the engine is a probabilistic, emergent surprise generator rather than a deterministic software tool. (Update: As of 2026, the EU is already phasing in requirements for human-in-loop interactions under the EU Artificial Intelligence Act ↗.)
If you want to see how this runs in practice, I made a companion tool that walks through both modes. There's a manual version that takes you through each stage individually, so you can see what the Engine is doing at each step. There's also a master prompt that automates Stages 1 and 2 entirely. The loop runs until parameters are passed. Stage 3 stays manual by design.

A companion tool to test the scaffolding in your own context.
governor-engine-scaffold.netlify.app/
How do we determine whether an output is sufficiently ‘ready’?
After Stage 2, the Engine scores its own output against three checks. If any fail, it loops back. All three must pass before the output reaches the Governor.
- Stress Score (SS): Did it hold up under pressure? Measures how many of the adversarial critiques raised in Stage 2 were actually addressed. The bar is set at 90% by user, 9 out of 10 Red-Hat challenges need a credible response before the output is considered stable.
- Drift Rate (DR): Is it still improving? Tracks how much the output changes between loops. If the change drops below 10%, further looping won't help. The output has plateaued. This does take effect in a clean post-Stage 2 draft generation, and would only start on any recursive loops since it needs a prior version to perform drift checks.
- Grounding Check (GC): Does it hold up in your added context? This only kicks in from the second loop onwards, once the Governor has added grounding context in Stage 3. It measures whether the Engine has taken that context on board and applied it. It ensures that the output logic is sound not just in isolation, but it needs to survive contact with the real constraints you've introduced.Below is a scale I developed for Grounding Check, not an established standard.
3 questions had to be asked after every stage. Did it survive a stress test? Has it stopped changing meaningfully? Does it actually make sense based on added context? If all 3 answers were yes, we moved forward.
In the companion tool, I also repackaged these instructions into a single, LLM-agnostic master prompt with instructions to loop and test recursively until the passing criteria are met.
Below are several competing frameworks and how they measured against the 3-Stage Process. Note that these aren’t rigorous measurements by any means.
A Note on Weaknesses of This Scaffold
In attempt to add rigour, the Governor-Engine Scaffold consumes token heavily (tested on Alphabet’s Gemini and Anthropic’s Claude). However, users are able to adjust passing parameters to fit whatever level of rigour the use case demands. This in theory allows control on token use. In fact, an earlier draft of the diagram required Stage 1 and Stage 2 to run their own recursive checks and loop within each stage. Testing and retesting variants of these master prompts caused me to almost hit the 5-hour limit on Claude Pro.
The obvious next problem to solve is efficiency, which I suspect data scientists and LLM engineers are already working on it.
So what does enterprise trust actually mean?
As I worked through the fears, scaffolding, and metrics, a clearer picture of what trust actually requires started to form. I believe there’s 4 aspects will make it a more palatable for adoption:
- Verification and hallucination control matters most upstream. The ability to detect, measure, and flag inconsistencies before outputs are acted on, not after.
- Closely linked is auditable transparency, not a full explainability layer, which tends to be technically complex and often misleading, but enough of a reasoning trail that a human governor can interrogate the output meaningfully.
- Beyond that, reproducible frameworks. Prompting structures that behave consistently across similar inputs are where prompt engineering disciplines matter most, not for performance, but for predictability.
- And finally, standardised governance artefacts. Design of trust artefacts should be portable, reusable controls that can be adopted across teams rather than reinvented each time a new pilot launches.
None of these are purely technical problems. All of them are, a combination of process, people, and design problems.
The deeper question
I feel organisations getting the most from GenAI aren't the ones who've found a way to trust the model unconditionally. They're the ones who've designed systems where outputs are always accountable to a human with the context, the authority, and the scaffolding to interrogate them. (Update: There’s a growing industry termed Observability).
The irony wasn't lost on us. GenAI was being sold everywhere as the great productivity unlock, and there we were, watching employees hesitate at the threshold. The hype had arrived. The trust hadn't.
This pattern isn't new. The Gartner Hype Cycle↗ has a name for it, every transformative technology ‘crests’ on inflated expectations before the inevitable slide into disillusionment. What follows, for the technologies that survive, is a slower climb built on realistic, hard-won understanding. Just like the Dot-com Bubble, GenAI is no different.
When the ‘crest’ breaks, the loudest voices quiet down and the more useful ones, the practitioners, the level-headed adopters, the people who've actually tried to get the blimp off the ground, start to be heard. Leadership will finally get their GenAI tool for deep enterprise use cases, but probably only after enough pilots stall.
To me, the probabilistic engine is powerful. Taming it isn't about constraining it. It's about knowing exactly who's holding the reins.

I'll also be the first to admit this is one slice of a much larger problem. Properly solving for trust in enterprise GenAI requires a multi-specialist efforts from ML engineers, compliance leads, legal, change management, and many more. This piece approaches it from a design and governance angle, which is a limited one by definition. Take it as solutioning from that vantage point, not a complete answer.
That said, this piece is my attempt at exploring whether that answer can be made portable. It draws on established ML concepts and cognitive science, but the intent was never purely theoretical. I wanted to see if the conditions for trust, verification, auditability, human oversight, could be packaged into something any non-technical staff could pick up, regardless of their technical setup. The companion tool is the practical test of that. Whether it holds in your context is the real question.
A small footnote: after publishing this, Anthropic released /Skills and .md, and I see it as scaffolding that operate on similar principles. Seems that 2026 is shaping up to be the year the industry stops treating human oversight as a philosophical position and starts treating it as an engineering requirement.
Additional reading
- Jerry, B., Moreno, L., and Martínez, P. (2025). Human Oversight-by-Design for Accessible Generative IUIs. Universidad Carlos III de Madrid.
- Codreanu, T. (2025). Cooperation After the Algorithm: Designing Human-AI Coexistence Beyond the Illusion of Collaboration. Imperial College London.
© 2025–2026 Kevyn Leong